
Nöral ağlar, verilerden örüntü öğrenerek sınıflandırma, tahmin, sıralama ve üretim (generative) gibi görevleri yerine getirebilen parametrik modeller ailesidir. Modern yapay zekâ uygulamalarında; görüntü işleme, doğal dil işleme, konuşma tanıma, anomali tespiti, öneri sistemleri ve zaman serisi tahmini gibi alanlarda yaygın olarak kullanılmaktadır. Bu yaygınlığın temel nedeni, nöral ağların doğrusal olmayan ilişkileri yüksek boyutlu uzaylarda temsil edebilmesi ve büyük veri üzerinde ölçeklenebilir şekilde optimize edilebilmesidir.
Bu rehberde nöral ağların matematiksel temelleri, katman/nöron yapısı, ileri besleme (forward pass) ve geri yayılım (backpropagation) ile eğitim mantığı, kayıp fonksiyonları ve optimizasyon yöntemleri, düzenlileştirme (regularization) teknikleri, yaygın mimariler (MLP, CNN, RNN/LSTM/GRU, Transformer) ve pratikte sık karşılaşılan hatalar teknik ve kurumsal bir dille kapsamlı biçimde açıklanmaktadır.
Gerekenler listesi
Bu kavramsal rehber için ekstra bir gereksinim yoktur.
Uygulamalı ilerleme hedeflendiğinde genellikle şu altyapılar gereklidir:
- Lineer cebir (vektör, matris çarpımı, türev), temel olasılık/istatistik
- Programlama temeli (çoğunlukla Python)
- ML/DL araçları (PyTorch, TensorFlow), GPU/TPU gibi hızlandırıcılar (büyük modeller için)
Nöral ağların teknik tanımı ve temel bileşenleri
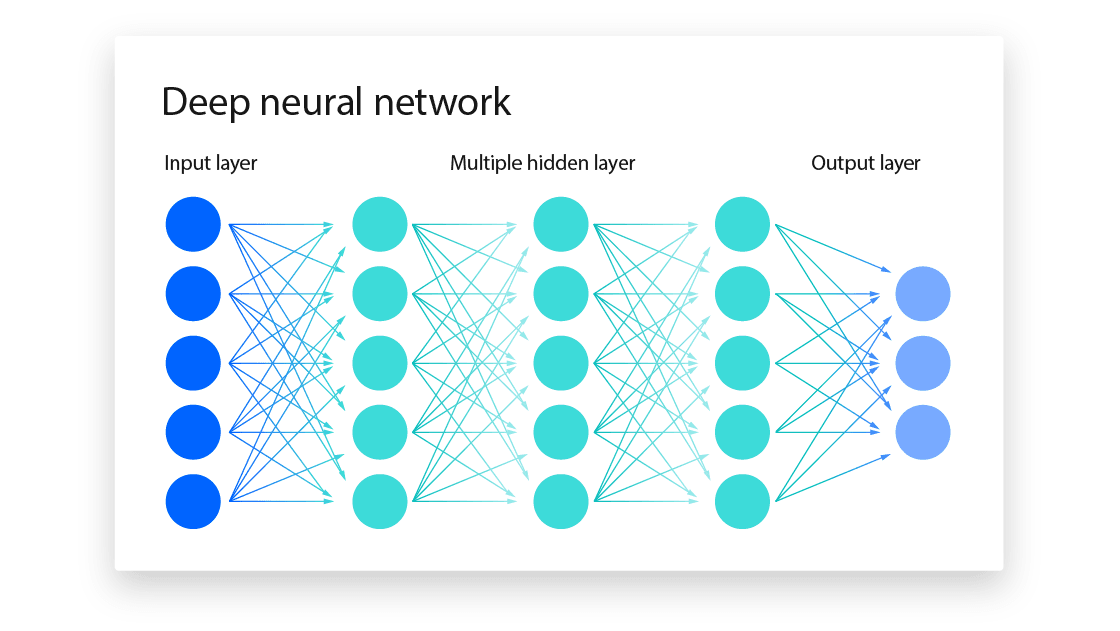
Adım 1: Modelin temel formu (nöron ve katman)
Bir nöron, girdilerin ağırlıklı toplamını alır ve doğrusal olmayan bir aktivasyonla dönüştürür. Tek bir nöron için temel ifade şu şekildedir:
- Girdi: \(x \in \mathbb{R}^d\)
- Ağırlık: \(w \in \mathbb{R}^d\)
- Bias: \(b \in \mathbb{R}\)
- Ön-aktivasyon: \(z = w^\top x + b\)
- Çıkış: \(a = \phi(z)\)
Burada \(\phi(\cdot)\) aktivasyon fonksiyonudur. Bir katman, çok sayıda nöronun birlikte matris formunda ifade edilmesidir:
- \(W \in \mathbb{R}^{m \times d}), (b \in \mathbb{R}^{m}\)
- \(z = Wx + b\)
- \(a = \phi(z)\)
Bu yapı, “tam bağlantılı” (fully connected / dense) katman olarak adlandırılır.
Adım 2: Çok katmanlı algılayıcı (MLP) ve temsil gücü
Çok katmanlı bir ağ (MLP), ardışık doğrusal dönüşümler ve doğrusal olmayan aktivasyonlardan oluşur:
\(a^{(0)} = x,\quad z^{(l)} = W^{(l)} a^{(l-1)} + b^{(l)},\quad a^{(l)} = \phi(z^{(l)}\)
Yeterli genişlikte ve uygun aktivasyonlarla MLP’lerin geniş bir fonksiyon sınıfını yaklaşık olarak temsil edebildiği bilinir (evrensel yaklaşım yaklaşımı). Pratikte temsil gücü; veri, mimari, düzenlileştirme ve optimizasyonla sınırlanır.
Adım 3: Aktivasyon fonksiyonları (neden gerekli?)
Aktivasyonlar doğrusal olmayanlık katar; aksi halde çok katmanlı yapı tek bir doğrusal dönüşüme indirgenir. Yaygın aktivasyonlar:
- ReLU: \(\max(0, z)\) — hızlı, pratikte başarılı; “ölü ReLU” riski bulunur.
- Leaky ReLU / PReLU: Negatif bölgede küçük eğim; ölü nöron riskini azaltır.
- Sigmoid: \(1/(1+e^{-z})\) — olasılık çıkışlarında; doygunluk bölgelerinde gradyan küçülmesi görülebilir.
- Tanh: \(\tanh(z)\) — sıfır merkezli; yine doygunluk riski vardır.
- Softmax: Çok sınıflı çıktı katmanında olasılık dağılımı üretir.
Eğitim süreci: ileri besleme, kayıp ve geri yayılım
Adım 1: İleri besleme (forward pass)
Model, girdiyi katmanlardan geçirerek \(\hat{y}\) tahmini üretir. Bu tahmin, hedef \(y\) ile karşılaştırılmak üzere kayıp fonksiyonuna iletilir.
Adım 2: Kayıp fonksiyonları (loss)
Kayıp, modelin hatasını skalar bir değere indirger ve optimize edilecek hedefi tanımlar:
- Regresyon: MSE (ortalama karesel hata)
\(\mathcal{L} = \frac{1}{N}\sum_{i=1}^{N} (y_i – \hat{y}_i)^2\)
- İkili sınıflandırma: Binary Cross-Entropy
- Çok sınıflı sınıflandırma: Cross-Entropy + Softmax
- Dengesiz veri: Focal Loss, class weighting
- Sıralama/metric learning: Triplet loss, contrastive loss
Kayıp fonksiyonu seçimi, hedef görevin istatistiksel doğasına uygun yapılmalıdır.
Adım 3: Geri yayılım (backpropagation) ve gradyanlar
Amaç, parametreler \( \theta = {W,b}\) için \(\nabla_\theta \mathcal{L}\) gradyanlarını hesaplamaktır. Geri yayılım, zincir kuralı ile katman katman türevlerin geriye doğru hesaplanmasıdır. Bu sayede her parametrenin kaybı ne kadar etkilediği bulunur.
Adım 4: Optimizasyon (SGD, Adam, vb.)
Parametre güncellemesi tipik olarak şu şemayı izler:
\(\theta \leftarrow \theta – \eta \nabla_\theta \mathcal{L}\)
- SGD: basit ve güçlü; momentum ile hızlanır.
- Momentum / Nesterov: vadilerde daha stabil ilerleme.
- Adam / AdamW: adaptif öğrenme oranı; pratikte yaygın. AdamW, ağırlık çürümesini (weight decay) daha doğru uygular.
- Öğrenme oranı zamanlaması: cosine annealing, step decay, warmup; eğitim kararlılığını belirgin etkiler.
Genelleme ve düzenlileştirme teknikleri
Adım 1: Aşırı öğrenme (overfitting) ve underfitting
- Overfitting: eğitim başarısı yüksek, test başarısı düşük; model veriyi ezberler.
- Underfitting: hem eğitim hem test başarısı düşük; model kapasitesi veya eğitim yetersizdir.
Adım 2: Düzenlileştirme yöntemleri
- L2 / weight decay: büyük ağırlıkları cezalandırır.
- Dropout: eğitimde nöronları rastgele kapatır, eş-uyumu (co-adaptation) azaltır.
- Early stopping: doğrulama kaybı kötüleşmeden eğitimi durdurur.
- Data augmentation: özellikle görüntüde; genellemeyi güçlendirir (kırpma, döndürme, renk jitter vb.).
- Label smoothing: sınıflandırmada aşırı emin tahminleri azaltır.
- Batch Normalization / Layer Normalization: dağılım kaymasını azaltır, gradyan akışını iyileştirir.
Yaygın mimariler ve hangi problemde neden tercih edilir?
Adım 1: MLP (Dense ağlar)
Yapılandırılmış tabular veriler, basit sınıflandırma/regresyon görevleri için temel seçenektir. Özellik mühendisliği (feature engineering) çoğu zaman performansı belirgin etkiler.
Adım 2: CNN (Evrişimli sinir ağları)
Görüntüde uzamsal yerel örüntüleri yakalamak için evrişim (convolution) kullanılır. CNN’ler; ağırlık paylaşımı ve yerel alıcı alan (receptive field) sayesinde parametre verimliliği sağlar. ResNet gibi atlama bağlantıları (skip connections) derin ağların eğitimini kolaylaştırır.
Adım 3: RNN / LSTM / GRU
Sıralı verilerde (metin, zaman serisi) geçmiş bağlamı taşımak için tasarlanmıştır. RNN’lerde gradyan sönmesi/taşması görülebilir; LSTM/GRU kapı mekanizmaları ile bu sorunları azaltır. Güncel NLP’de Transformer’lar baskın olsa da, bazı zaman serisi senaryolarında RNN türevleri hâlâ kullanılmaktadır.
Adım 4: Transformer
Self-attention mekanizması ile uzak bağımlılıkları verimli şekilde modelleyebilir. Dil modelleri (LLM’ler), çeviri, özetleme ve çok modlu sistemlerde standart yaklaşım haline gelmiştir. Katman normalizasyonu, attention başlıkları (multi-head) ve pozisyon bilgisi (positional encoding) temel bileşenlerdir.
Pratik iş akışı: veri, değerlendirme ve dağıtım
Adım 1: Veri hazırlığı ve bölme
- Eğitim/Doğrulama/Test ayrımı sızıntı (data leakage) olmayacak şekilde yapılmalıdır.
- Özellikle zaman serisinde kronolojik bölme gereklidir.
- Ölçekleme/normalizasyon adımları yalnızca eğitim verisine göre “fit” edilip diğerlerine uygulanmalıdır.
Adım 2: Değerlendirme metrikleri
- Sınıflandırma: Accuracy, precision/recall, F1, ROC-AUC
- Regresyon: MAE, RMSE, R²
- Dengesiz sınıflar: PR-AUC, sınıf bazlı metrikler, confusion matrix
Adım 3: Dağıtım (inference) gereksinimleri
- Gecikme (latency), bellek, model boyutu ve donanım hedefleri belirleyicidir.
- Quantization (INT8), pruning ve distillation ile model küçültme mümkündür.
- Model izleme (drift, performans düşüşü) ve yeniden eğitim stratejileri operasyonel kalite için gereklidir.
İpuçları, sık yapılan hatalar ve sıkça sorulan sorular
Sık yapılan hatalar
- Öğrenme oranının hatalı seçimi: çok yüksek oran patlamaya, çok düşük oran aşırı yavaşlamaya yol açabilir.
- Veri sızıntısı: test bilgisinin eğitim sürecine dolaylı karışması metrikleri yapay yükseltir.
- Dengesiz veri ihmal edilmesi: accuracy yüksek görünürken azınlık sınıfı başarısız olabilir.
- Yanlış kayıp-metrik eşleşmesi: hedef iş ile uyumsuz kayıp/çıktı katmanı seçimi performansı düşürür.
- Aşırı model kapasitesi: küçük veri üzerinde büyük ağlar ezberlemeye yatkındır.
Teknik ipuçları
- Başlangıç için ReLU + He initialization, sınıflandırmada Cross-Entropy, optimizasyonda AdamW + uygun scheduler iyi bir temel oluşturur.
- Batch size, öğrenme oranı ve weight decay birlikte ayarlanmalıdır (özellikle büyük modellerde).
- Gradient clipping, RNN/zor eğitimlerde stabilite sağlar.
- Karşılaştırmalı deneylerde aynı veri bölmeleri ve sabit seed kullanımı tekrar üretilebilirlik sağlar.
Sıkça sorulan sorular
Nöral ağlar her zaman en iyi çözüm müdür?
Her problem için zorunlu değildir. Tabular veride ağaç tabanlı yöntemler (GBDT türleri) bazı senaryolarda daha güçlü olabilir; seçim probleme, veriye ve operasyonel kısıtlara göre yapılmalıdır.
Derin öğrenme ile nöral ağ arasındaki fark nedir?
Derin öğrenme, çok katmanlı (derin) nöral ağların büyük veri ve hesaplama ile eğitilmesini merkeze alan yaklaşımdır. Nöral ağ, daha genel bir şemsiye kavramdır.
Model neden doğrulamada düşerken eğitimde yükselir?
Bu tipik bir overfitting göstergesidir. Daha fazla veri, daha güçlü düzenlileştirme, veri artırma, erken durdurma ve model basitleştirme gibi yöntemler uygulanmalıdır.
Editör notu
Nöral ağlar; doğrusal olmayan fonksiyonları öğrenebilen, gradyan tabanlı optimizasyonla eğitilen ve güncel yapay zekâ sistemlerinin omurgasını oluşturan modellerdir. Başarılı sonuçlar; uygun mimari seçimi, doğru kayıp/optimizasyon ayarları, veri kalitesi ve düzenlileştirme yaklaşımının birlikte ele alınmasıyla elde edilmektedir.